N-grams
N-grams
N-grams 是一种重要的语言建模技术,主要用于识别概率、预测文本以及生成句子等自然语言处理任务。
语言模型中的概率分配
在语言模型中,系统会根据单词在给定上下文中跟随提示的可能性来分配概率。早期的手动方法虽然有助于理解概念,但对于实际应用而言并不可行。
以开发企业服务聊天机器人为例,若希望模型能够回答用户提出的各类问题,手动为所有可能的输入分配概率显然是不现实的。这种方式不仅限制了模型的应答范围,而且在面对新的问题时需要不断补充概率数据,维护成本极高。即使针对有限的问题集合,手工分配概率也需要投入大量时间成本。
上下文的重要性
如何确定文本中词项的概率分布?以短语"桌山很美丽"、"桌山很大"为例,这些搭配符合语言习惯,而"桌山是穿山甲"、"桌山是午夜"则显得不自然。这种差异反映了语言中词项的共现规律。
分析文本集合并观察词项的实际使用模式是确定概率的自然方法。英国语言学家约翰·鲁珀特·弗斯(John Rupert Firth)提出的观点"你应当根据一个词的左右邻词来了解它"为此类方法奠定了理论基础。
现代语言模型采用该理念的计算版本,通过统计分析哪些词项频繁共现或出现在相似上下文中来估计其联合概率。例如,模型可识别"椰菜炒饭"中"饭"紧随"椰菜"的高概率关系。相反,对于"椰菜骰子"这类罕见搭配,模型会分配较低的概率值。这一原则同样适用于更大语言单元的共现关系,如问题与答案的配对模式。
数学表示
词项共现关系及其条件概率可通过数学公式进行形式化表达:
表示在当前词为 的条件下,下一词为 的概率。
该概率可基于计数进行估计:
例如:
其中,分子 为文本集合中"椰菜饭"组合的出现频次,分母 为"椰菜"一词的总出现次数。该公式体现了特定词项紧跟前置词项的条件概率。
N-grams 概念
上述理念可扩展至词序列预测任务,即 N-gram 模型。N-gram 指文本中连续出现的 n 个词项构成的序列。通过统计大规模语料中不同 N-grams 的出现频率,可有效捕捉语言模式。
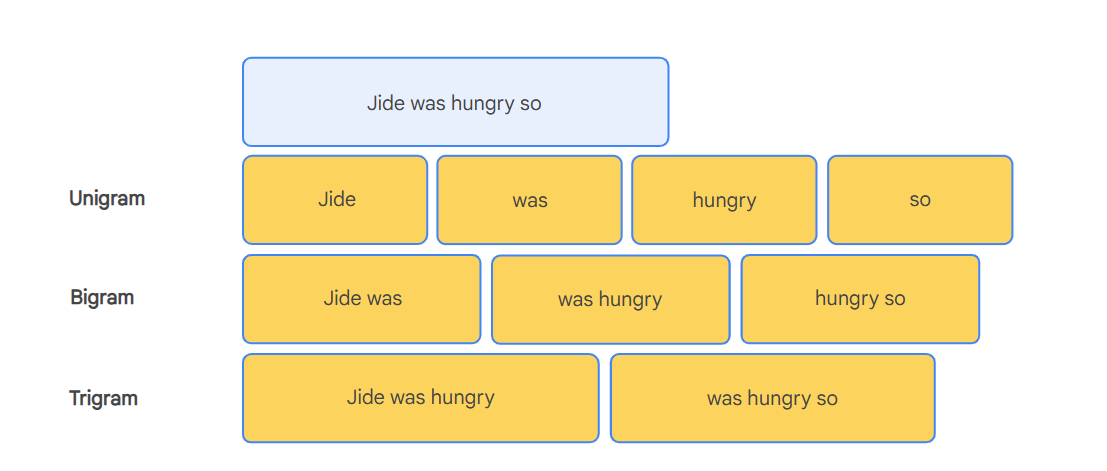
以短语"Jide was hungry so"为例:
一元语法()
Jide, was, hungry, so
二元语法()
Jide was, was hungry, hungry so
三元语法()
Jide was hungry, was hungry so
以三元语法为例,若"New York City"在数据集中出现300次,而"New York York"罕见出现,则可推断"City"更可能紧跟"New York"。该关系可形式化为:
此类模型被称为 N-gram 语言模型,其概率估计基于数据集中 N-grams 的统计计数。通过 N-gram 计数计算概率的方法为自动预测下文、句子补全及文本生成提供了有效途径。
上下文窗口
"New York"后预测"City"体现了语言模型中的关键概念——上下文窗口。上下文窗口指影响模型对下一个词预测的前置信息范围。
在 N-gram 语言模型中,上下文窗口恒由当前词前的 个词构成。以二元语法模型为例,其上下文窗口大小为1,仅基于前一个词进行预测;三元语法模型的上下文窗口大小为2,基于前两个词进行预测。
在实际应用中,N-gram 方法提供了构建语言模型的简单而有效的方式。尽管现代大型语言模型采用更复杂的神经网络架构,N-grams 仍是理解语言建模基本原理的重要基础。
N-grams的局限性
N-grams虽然能够用于捕捉语言中的模式,但存在一些局限性。
在之前实验中探索的N-gram语言模型能够基于提示预测下一个词序列,但它有几个局限性。
在构建和使用N-gram模型时,可以观察到一些缺点,例如:
语料库规模小:Africa Galore数据集规模较小,限制了模型提取语言有意义模式的能力。
无法处理未出现在数据集中的词语:如果N-gram模型遇到数据集中未出现的上下文序列(n-gram),它将无法估计下一个词的概率并停止生成文本。
可预测性和重复性:模型依赖频率计数来生成词语,使得输出重复。由于数据集较小,它很可能会每次都生成相同的文本结构。
缺乏上下文感知能力:由于N-grams只考虑前 个词,它们忽略了长距离依赖性。例如,对于提示"Jide was hungry, so she went looking for",三元模型将基于"looking for"来预测下一个词,但不会保留"Jide being hungry"这一更重要的广泛上下文。此外,模型有时会错误地为Jide指定性别,使用"he"来指代她。